2021. 7. 21. 14:12ㆍSpark

1. Apache Spark란..
Apache Spark는 오픈소스이며, 범용적인 목적을 지닌 분산 클러스터 컴퓨팅 프레임워크으로서 Fault Tolerance & Data Parallelism을 가지고 클러스터들을 프로그래밍할 수 있게 도와준다. Apache Spark에서는 RDD, Data Frame, Data Set의 3가지 API를 제공하는데, 이러한 데이터를 바탕으로 In-memory 연산을 가능하도록 하여 디스크 기반의 Hadoop에 비해 성능을 약 100배 정도 끌어올렸다.
다만. 성능을 재대로 활용하기 위해서는 노력이 필요..
2. Spark의 구조
스파크는 스파크를 보조하는 YARN 그리고 HDFS와 다양한 API들로 구성되어 다양한 연산처리를 할 수 있도록 구성되어 있다. 아래 그림을 한번 살펴 보자.
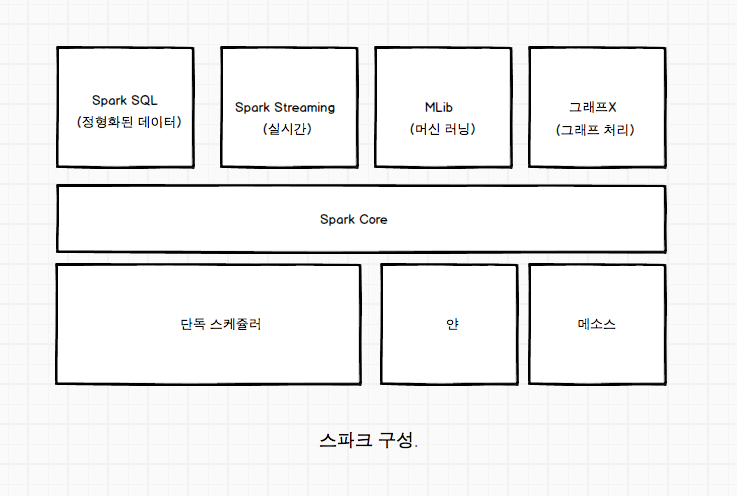
이중 중요한 몇가지 사항을 살펴 보도록 하자.
- YARN (얀) : YARN은 수백, 수천개의 노드로 구성된 클러스터에서 작업이 제출되면 수많은 작업들을 관리하고, 특정 작업에 사용할 자원(CPU, RAM)을 관리해주는 분산자원관리 기능을 담당한다. 이를 통하여 Spark Cluster를 관리하고 운영이 가능하다.
- Spark Core : 작업 스케줄링, 메모리 관리, 장애 복구, 저장 장치와의 연동 등등 기본적인 기능들로 구성됨. RDD(Resilent Distributed Datasets)를 정의 하는 API 의 기반이 되며, 이것이 주된 스파크 프로그래밍의 추상화 구조이다.
- 다양한 API : Spark의 Structured Data를 처리할 수 있는 SQL, 실시간 Streaming으로 데이터를 처리하는 Spark Streaming 다양한 ML 모델을 사용할 수 있는 Spark ML 등등 여러가지 활용할 수 있는 다양한 도구들이 준비 되어 있다.
3. Spark YARN의 활용
실제로 Task를 구동하는 Spark Executors와 Executors를 스케줄링하는 Spark Driver로 구성된 Spark jobs는 2가지 배치 모드 중 한가지로 실행될 수 있다. 2가지 모드를 잘 이해해야 적당한 메모리 할당량을 설정하고, jobs를 예상한대로 제출할 수 있다. 각각의 모드는 다음과 같다.
1. Cluster Mode(클러스터 모드)
Cluster Mode는 모든 것들은 Cluster에서 구동된다. Job을 Client에서 구동할 수 있으며, Client가 꺼져도 Cluster에서 job은 처리된다. Spark Driver는 YARN Application Master 내부에 캡슐화 되어있다. 오랜 작업시간이 필요한 경우, Cluster Mode를 사용하는 것이 좋다.

2. Client Mode(클라이언트 모드)
Spark Driver는 Client에서 구동이 된다. 만약 Client가 꺼지면, job은 fail하게 된다. 반면에 Spark Executors는 여전히 Cluster에서 구동되는데, 스케줄링을 위해 Yarn Application Master가 생성된다. Client Mode는 interactive jobs(실시간 쿼리 or 온라인 데이터 분석 등)에 적합하다.

참고자료
'Spark' 카테고리의 다른 글
| Spark - Docker로 Spark Cluster + Jupyterlab 구성 (2) | 2021.07.21 |
|---|---|
| PySpark - SparkSQL Structured Streaming Kafka (0) | 2021.07.13 |
| PySpark - Kafka Structured Streaming 설정 (0) | 2021.07.13 |
| Spark SQL - DataFrame Row 개수 구하기 (0) | 2021.07.13 |
| PySpark - Azure Event Hub Structured Streaming 설정 (0) | 2021.07.05 |